

PDFからタイトルや作成者などのメタデータを取得するコードをご紹介します。
PyPDF2のインストール
今回のサンプルではPythonでPDFを扱えるライブラリ「PyPDF2」を使っていきます。
GitHub - py-pdf/pypdf: A pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files
A pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files - py-pdf/pypd...
github.com
pipコマンドでインストールできますので、あらかじめインストールしておきましょう。
pip install PyPDF2そもそもPDFのメタデータとは?
PDFにはメタデータを格納することができます。
例えば、PowerPointで作成したPDFには、表題がタイトルとして格納されています。Adobe Acrobat Readerなどのアプリケーションで確認することができます。
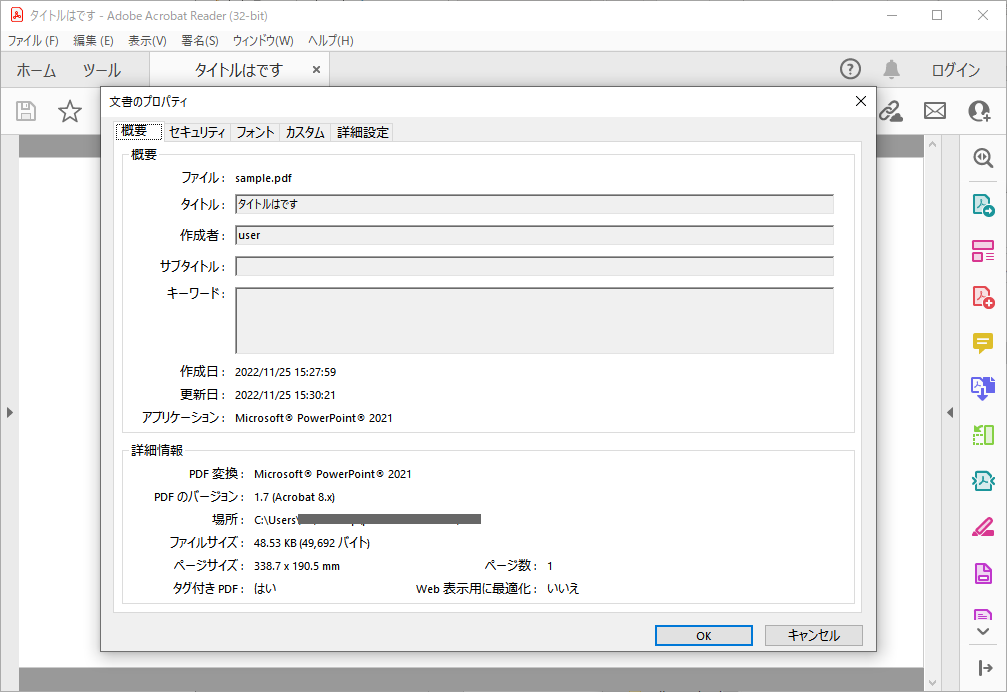
今回はPythonでこれらのデータを取得する方法をご紹介します。
タイトルを取得するには?
メタデータからタイトルを取得してみましょう。
from PyPDF2 import PdfReader
# PDFを読み込む
reader = PdfReader("sample.pdf")
# メタデータを取得する
meta = reader.metadata
# タイトルを出力
print(meta.title)
# サブタイトルを出力
print(meta.subject)上記PDFに対して実行すると、以下のように出力されます。
タイトルはです
NonePDFの作成者を取得するには?
メタデータに含まれている場合は、PDFを作成したユーザー名も取得することができます。
from PyPDF2 import PdfReader
# PDFを読み込む
reader = PdfReader("sample.pdf")
# メタデータを取得する
meta = reader.metadata
# 作成者を出力
print(meta.author)

コメント